Count-Min Sketch Explained: Trillions of Counters
Search for a command to run...
No comments yet. Be the first to comment.
Quick Answer: SQL injection attacks exploit vulnerabilities in how web applications construct database queries. By sending malicious SQL code through user input fields (like search bars), attackers ca
Stop wasting your context window explaining industry standards to LLMs. Large Language Models already have best practices baked into their training data; you just need to activate those specific regio
The Netflix Keeper Test asks managers: "If this engineer resigned today, would you fight to keep them?" While it ensures high talent density, I believe it often destroys psychological safety. For most
Quick Answer: No, AI agents won't replace software engineers, but they are flipping the table on how we work. While agents excel at writing generic, path-of-least-resistance code, they lack opinion. H
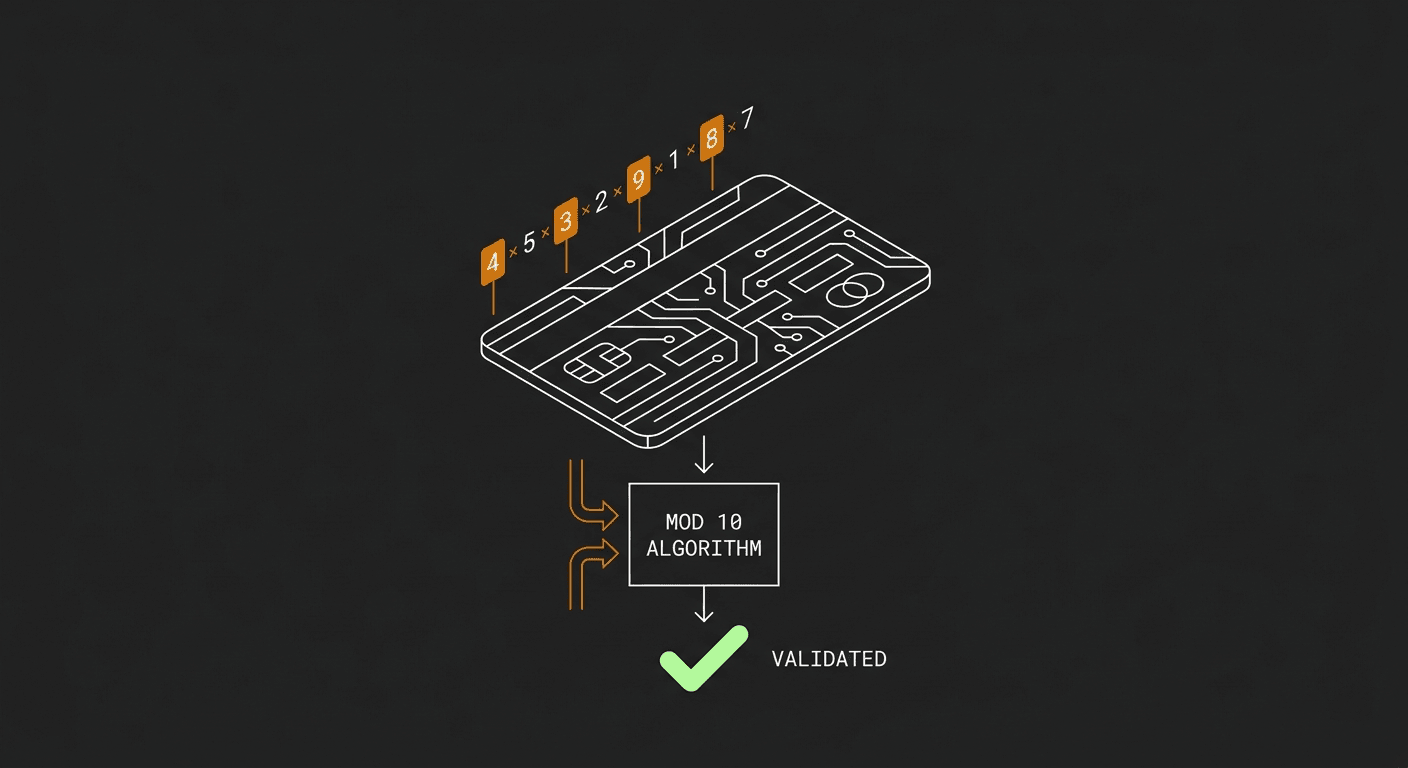
I use the Luhn algorithm to validate credit cards instantly on the client side without querying a bank. By doubling every second digit from the right and summing them, the browser checks if the final
Quick Answer: A Count-Min Sketch is a probabilistic data structure used to estimate the frequency of events in massive datasets. By running items through multiple hash functions and storing counts in fixed-size arrays, it compresses trillions of counters into kilobytes of memory. It guarantees no underestimations but allows slight overestimations due to hash collisions.
If there is one thing I constantly think about when designing high-volume systems, it is how quickly memory gets devoured. Let's say your team is building an analytics engine for an ad network. You need to answer a seemingly basic question: How many times has each user seen each ad? If you have 2 billion users and 10 million ads, you are staring down 20 trillion unique counters. Storing that in a standard database table or hash map will eat up terabytes of RAM.
But what if I told you that you could store that exact same frequency data in just 16 kilobytes of memory? That is exactly what a Count-Min Sketch allows us to do.
A hash map requires memory that scales linearly with the number of unique items, which becomes impossibly expensive at massive scale. A Count-Min Sketch uses a fixed amount of memory by trading exact precision for highly accurate estimates.
When I look at our ad network scenario, allocating even a tiny 4-byte integer for 20 trillion counters demands massive memory overhead. A Count-Min Sketch avoids this by acting as a bounded probability structure. It does not store the keys (the user-ad pairs) at all. Instead, it relies on hashing to map an infinite stream of events into a strictly bounded memory footprint.
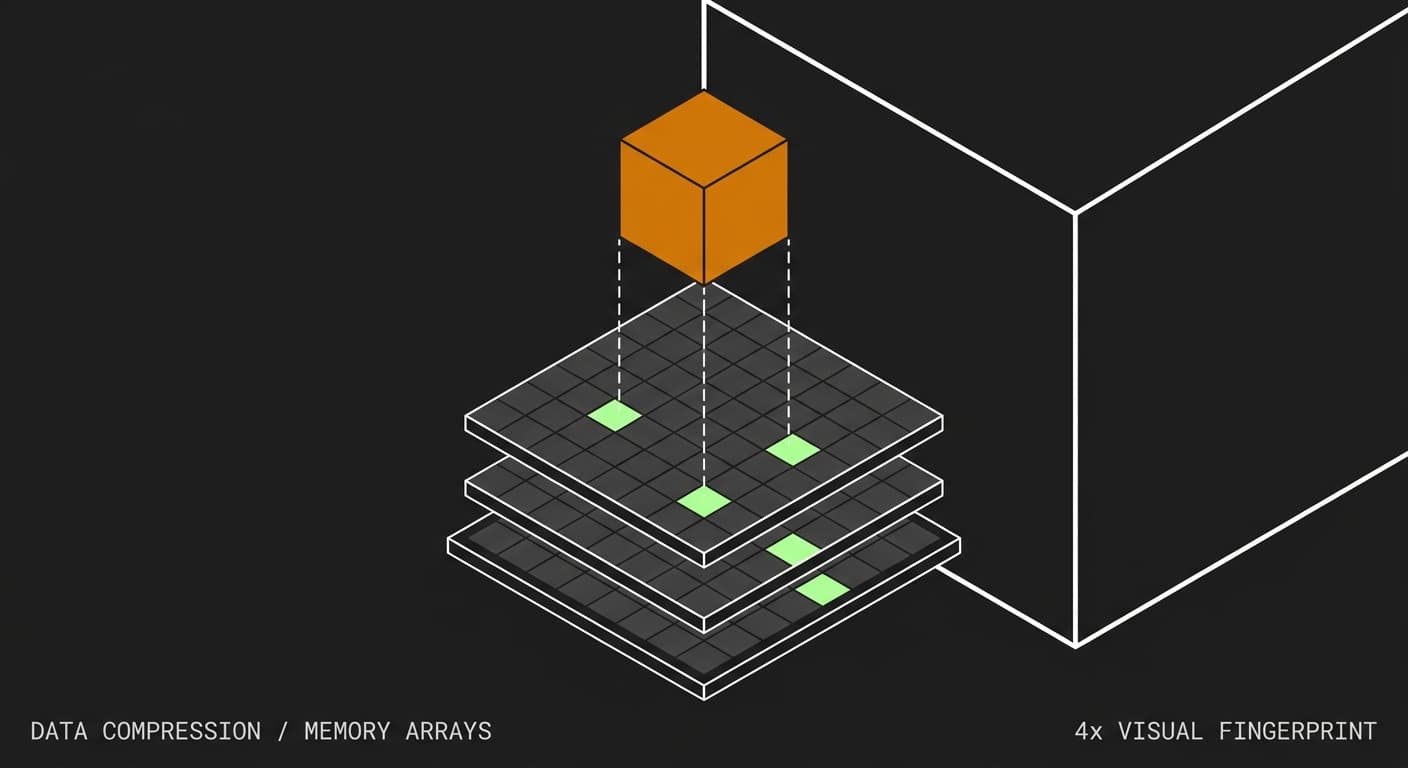
It uses a matrix of independent arrays and corresponding hash functions to generate a unique footprint for every item. When an item is processed, it is hashed multiple times to increment specific counters across the arrays.
The results from these hash functions act as a unique fingerprint for your item across the arrays.
Here is exactly how I break down the mechanics of inserting an item into a Count-Min Sketch:
To retrieve a count, you hash the item again using the same functions, look up the values in each array, and return the lowest number. Because hash collisions only ever inflate numbers, the minimum value is the most accurate estimate.
When you want to query the count, you take your item and run it through the exact same four hash functions. This gives you the fingerprint of your four array locations, returning four different numbers.
Because multiple different items might hash to the same index (a collision), some counters will be artificially high. But a counter can never be lower than the true frequency of your item. Therefore, returning the minimum value across your arrays filters out the noise from collisions. You get a mathematical guarantee that you are never going to have an underestimate.
A Count-Min Sketch is highly accurate, often exceeding 99% accuracy depending on the configured width and depth. You can predictably increase accuracy by adding more arrays and hash functions.
The only error you will encounter is an overestimate caused by hash collisions. However, the math works out in your favor remarkably fast. With just four arrays of 1,024 elements, the error rate is incredibly small. If you scale this up to just eight arrays and eight hash functions, the difference between your estimate and the actual real count hits 99.9% accuracy. I find it crazy that this structure is capable of storing trillions and trillions of counters in a footprint so small it can literally fit in a CPU cache.
It never technically gets "full" because it has a fixed size in memory. However, as you add a massive volume of items, the arrays become saturated. This increases the likelihood of hash collisions, which eventually reduces the accuracy of your estimates by artificially inflating the counts.
Generally, no. Because multiple items share the same counters due to hash collisions, decrementing a counter for one item would likely corrupt the counts of other completely unrelated items that happen to hash to that same bucket.
A Bloom Filter is a probabilistic data structure used to check if an item exists in a set (returning a boolean true or false). A Count-Min Sketch is used to estimate how many times an item has appeared in a stream (returning an integer frequency count).