djb2 Hash Function: String to Integer Algorithm Explained
Search for a command to run...
No comments yet. Be the first to comment.
Quick Answer: SQL injection attacks exploit vulnerabilities in how web applications construct database queries. By sending malicious SQL code through user input fields (like search bars), attackers ca
Stop wasting your context window explaining industry standards to LLMs. Large Language Models already have best practices baked into their training data; you just need to activate those specific regio
The Netflix Keeper Test asks managers: "If this engineer resigned today, would you fight to keep them?" While it ensures high talent density, I believe it often destroys psychological safety. For most
Quick Answer: No, AI agents won't replace software engineers, but they are flipping the table on how we work. While agents excel at writing generic, path-of-least-resistance code, they lack opinion. H
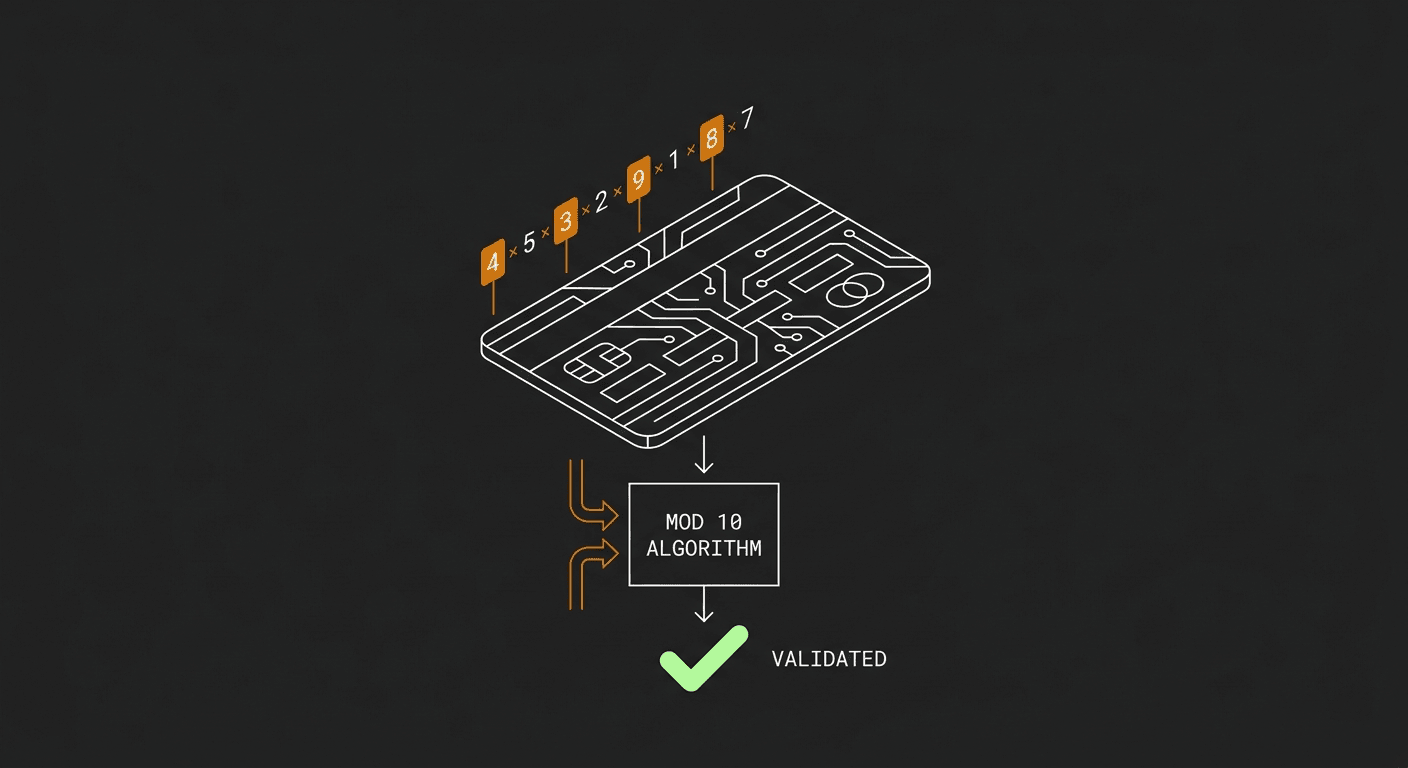
I use the Luhn algorithm to validate credit cards instantly on the client side without querying a bank. By doubling every second digit from the right and summing them, the browser checks if the final
Quick Answer: The djb2 hash function is a highly efficient algorithm that converts strings into integers, commonly used to place items into hash map buckets. It iterates through a string’s ASCII characters, multiplying a base hash (starting at the magic number 5381) by 33, and adding the current character's value.
Imagine your team is building an in-memory cache and you need to look up user data using their email addresses as the key. You don't want to scan every single record to find a match. Instead, you want a system that acts like a highly organized mailroom clerk: you hand them a string (the email), and they instantly tell you exactly which numbered bin (the integer) that user's data sits in.
That translation from a string to an integer index is the job of a hash function. There are plenty of complex hashing algorithms out there, but today I want to look at one of the simpler, classic implementations: djb2.
The djb2 hash function is a lightweight algorithm that takes an input string and deterministically converts it into a single integer. Software engineers primarily use it under the hood in hash maps and dictionaries to figure out which memory bucket a specific string ID should live in.
When you pass a key into a hash map, the underlying array needs a numeric index to store your data. djb2 is favored because it is incredibly fast to execute and generally provides a good distribution of keys across available buckets, meaning you don't end up with all your data clustered in one spot.
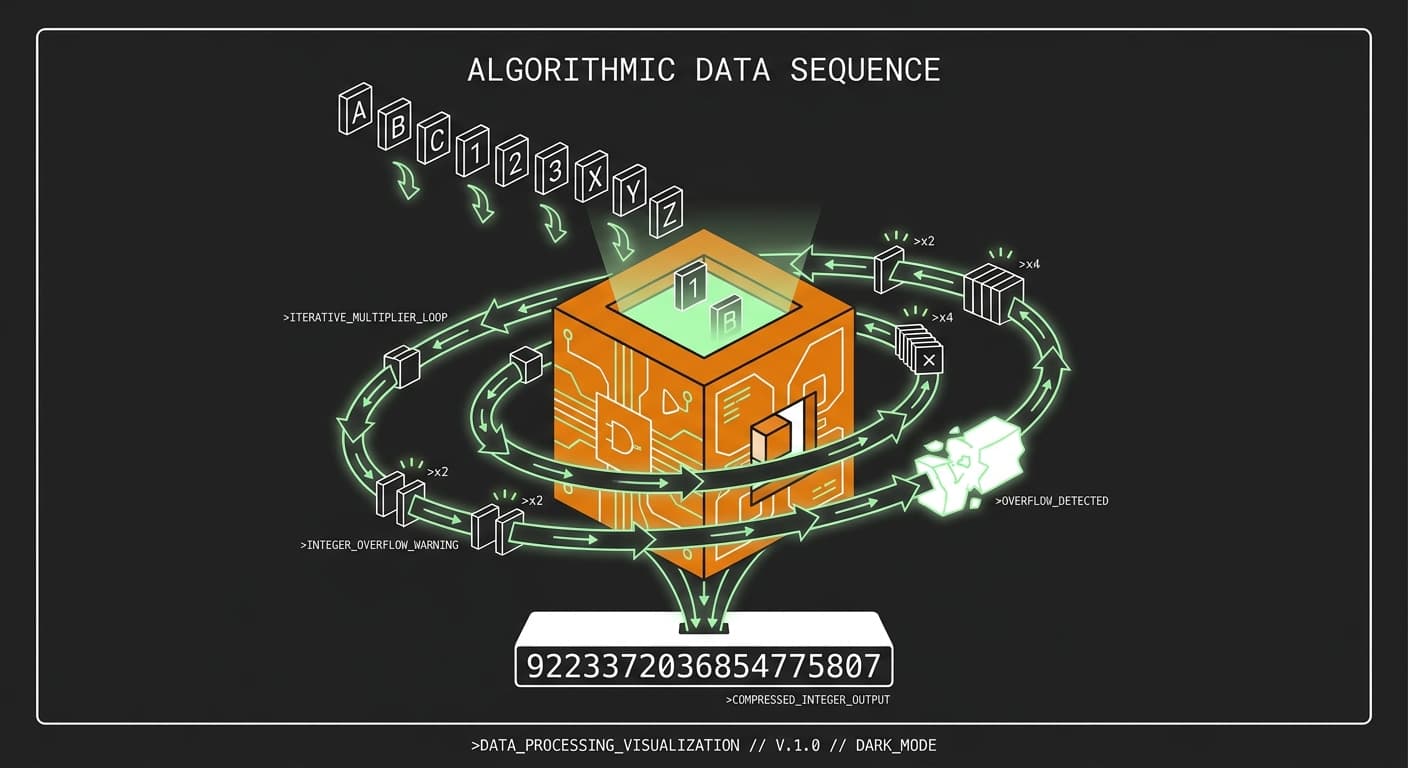
The algorithm starts with an initial "magic number" of 5381. For every letter in your string, it multiplies the current hash by 33 and adds the ASCII integer value of that specific character to generate a new hash.
Let's break down exactly how this works with the word "cat". In ASCII, the letters C, A, and T translate to 99, 97, and 116 respectively. The algorithm steps through the word one character at a time, applying the formula: new_hash = (old_hash * 33) + ASCII_value.
Here is how that calculation plays out step-by-step:
| Character | ASCII Value | Formula | Resulting Hash |
|---|---|---|---|
| (Start) | N/A | Initial Magic Number | 5381 |
| c | 99 | (5381 * 33) + 99 | 177672 |
| a | 97 | (177672 * 33) + 97 | 5863273 |
| t | 116 | (5863273 * 33) + 116 | 193488125 |
By the time we finish processing a tiny three-letter word, we've already generated a fairly large integer: 193,488,125.
If you were to write this out in code, it is exceptionally brief:
function djb2(str) {
let hash = 5381;
for (let i = 0; i < str.length; i++) {
hash = (hash * 33) + str.charCodeAt(i);
}
return hash;
}
Because the algorithm continually multiplies by 33 and adds new values, the resulting integer only ever goes up. When you hash a longer string, the value will inevitably hit the maximum integer limit of the system and cause an integer overflow, wrapping back around to the beginning.
This isn't a bug; it's a completely normal part of the process. In fixed-width integer environments (like a 32-bit integer in C), hitting INT_MAX means the number simply wraps around and continues calculating. Because this wrapping behavior is entirely deterministic, passing the same long string will always produce the exact same overflowed integer, which is all we really care about when routing keys to hash map buckets.
There is no deep, pure mathematical theorem behind the choice of 5381 and 33. These specific numbers were discovered via rigorous empirical testing to see which combinations produced the fewest collisions across large datasets of words.
When Dan Bernstein created the algorithm, the goal was practical performance rather than theoretical perfection. Testing revealed that these numbers provided an excellent spread. While 33 isn't a prime number, it works exceptionally well in practice because multiplying by 33 can be optimized at the hardware level using bitwise operations (specifically, shifting bits left by 5 and adding the original value).
No. The djb2 algorithm is designed purely for speed and data distribution in data structures like hash tables. It is easily reversible and provides absolutely no cryptographic security for things like passwords or sensitive data.
No, there are other multipliers used in different hashing algorithms. However, empirical testing showed that 33 distributes standard English text and programming symbols very evenly across hash map buckets, minimizing collisions compared to other small numbers.
Starting the hash at 0 is problematic because any leading null characters or zeroes in a key would have absolutely no effect on the early stages of the multiplication (since 0 multiplied by anything is 0). Starting with a non-zero odd number like 5381 ensures that every single bit of the input string influences the final integer.