How Database Reads Work: Pages, Buffer Pools, and Disk
Search for a command to run...
No comments yet. Be the first to comment.
Quick Answer: SQL injection attacks exploit vulnerabilities in how web applications construct database queries. By sending malicious SQL code through user input fields (like search bars), attackers ca
Stop wasting your context window explaining industry standards to LLMs. Large Language Models already have best practices baked into their training data; you just need to activate those specific regio
The Netflix Keeper Test asks managers: "If this engineer resigned today, would you fight to keep them?" While it ensures high talent density, I believe it often destroys psychological safety. For most
Quick Answer: No, AI agents won't replace software engineers, but they are flipping the table on how we work. While agents excel at writing generic, path-of-least-resistance code, they lack opinion. H
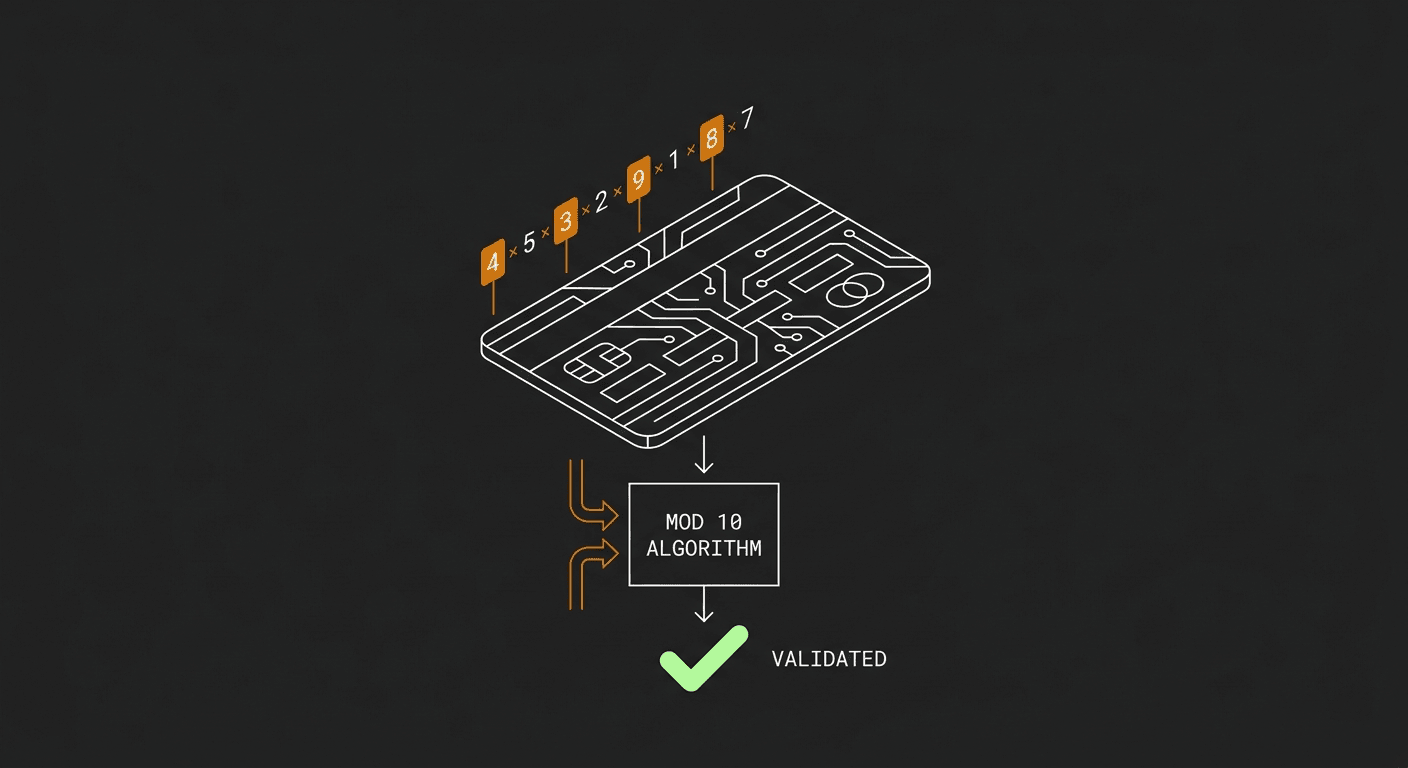
I use the Luhn algorithm to validate credit cards instantly on the client side without querying a bank. By doubling every second digit from the right and summing them, the browser checks if the final
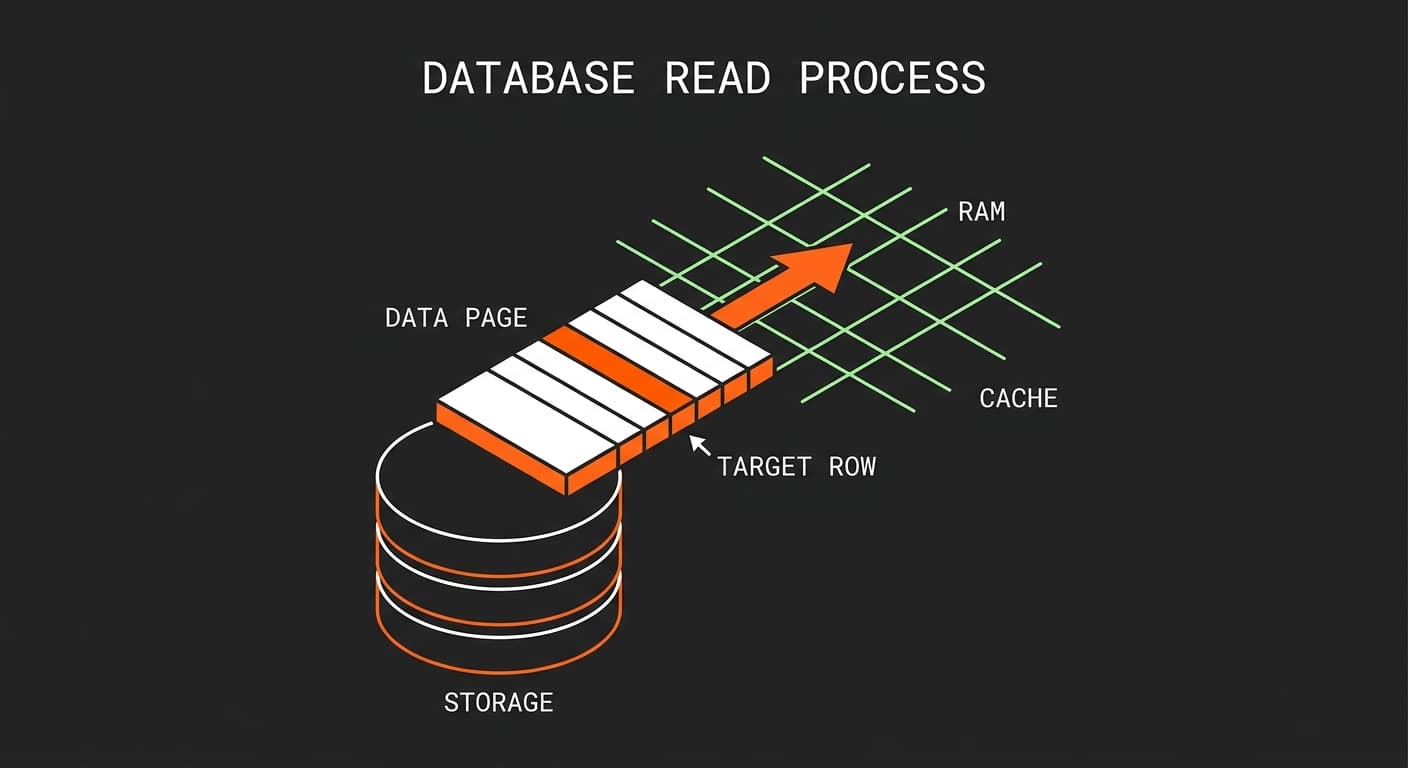
Quick Answer: When you query a database, it rarely reads a single row directly from disk. Instead, it relies on RAM. Databases load fixed-size blocks of data called "pages" (typically 8KB) into a memory cache known as the buffer pool. This minimizes slow disk reads and dramatically speeds up follow-on queries.
Let's say you need to fetch a specific order from your database. You write a standard query that looks something like this:
SELECT * FROM orders WHERE user_id = 6;
I see a lot of developers naively think the database engine behaves like a simple file reader: it spins up the physical disk, scans the orders table, finds the exact row for user 6, and hands that single row directly back to you.
In reality, 99% of the time, your database isn't touching the disk at all. And for that 1% of the time when it actually does go to disk, it absolutely is not returning a single row. It returns a page.
Databases rarely read single rows directly from the physical disk. Instead, they read larger, fixed-size blocks of data called pages, pulling them directly into a specialized RAM cache called the buffer pool.
To visualize this, imagine your team is building an e-commerce backend. When an API requests an order, the database doesn't send a forklift into the warehouse (the disk) just to retrieve a single AAA battery (the row). That would be wildly inefficient. Instead, it grabs the entire pallet (the page) and brings it to the staging area (RAM).
This means almost every read operation you execute is actually interacting with memory, not the physical hard drive.
A database page is the fundamental unit of storage in a relational database. It is a fixed-size container—usually about 8 kilobytes—that holds multiple rows of data alongside other structural information.
Because a page is 8KB, it contains a reasonable amount of information. When you insert records into a table, the database packs those rows into pages. The disk is essentially just a massive collection of these 8KB blocks. When the database engine needs to read or write, it operates entirely in terms of these pages, never in isolated rows.
When you execute a query, the database engine checks the buffer pool in RAM to see if the required index and data pages are already loaded. If the pages are missing, it fetches them from disk, stores them in memory, and then returns your result.
Here is the exact step-by-step execution flow when you run a simple SELECT query:
user_id column!).Databases read whole pages into RAM to optimize for future queries. Fetching data from a physical disk is an expensive operation, so loading adjacent rows simultaneously speeds up subsequent requests.
This concept relies heavily on spatial locality. If you load an entire page into RAM just to get one order for user 6, you have also loaded the adjacent rows into memory. When follow-on queries ask for user 7 or another related record, that data is likely already sitting directly in the buffer pool. You skip the slow disk read entirely.
Of course, this raises a logical next question: you obviously don't want to load your entire database into RAM. So, what happens when the buffer pool gets full? Well, that involves eviction algorithms, which is a topic for another video.
The buffer pool is a dedicated segment of RAM used by the database engine to cache table and index data. By keeping frequently accessed pages in memory, the database avoids slow disk I/O operations, making queries run exponentially faster.
In most major relational database systems, like PostgreSQL and SQL Server, the default page size is 8 kilobytes (8KB). Other databases might use 16KB or allow for custom page sizing, but 8KB is the industry standard.
When the buffer pool reaches its memory limit, the database must remove older data to make room for new pages. It typically uses algorithms like Least Recently Used (LRU) to evict pages that haven't been queried recently, ensuring the most active data remains in RAM.