Single Responsibility Principle for AI Sub-Agents
Search for a command to run...
No comments yet. Be the first to comment.
Quick Answer: No, AI agents won't replace software engineers, but they are flipping the table on how we work. While agents excel at writing generic, path-of-least-resistance code, they lack opinion. H
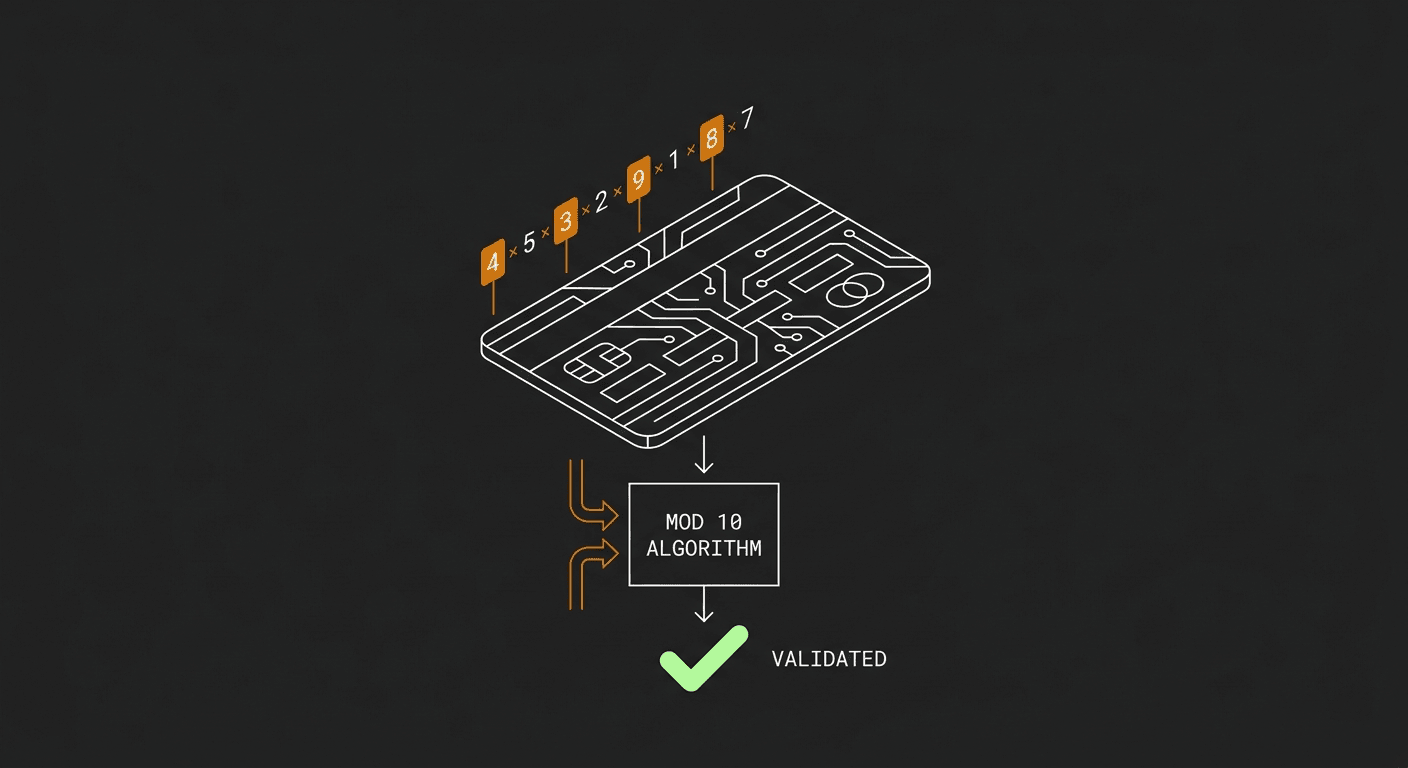
I use the Luhn algorithm to validate credit cards instantly on the client side without querying a bank. By doubling every second digit from the right and summing them, the browser checks if the final
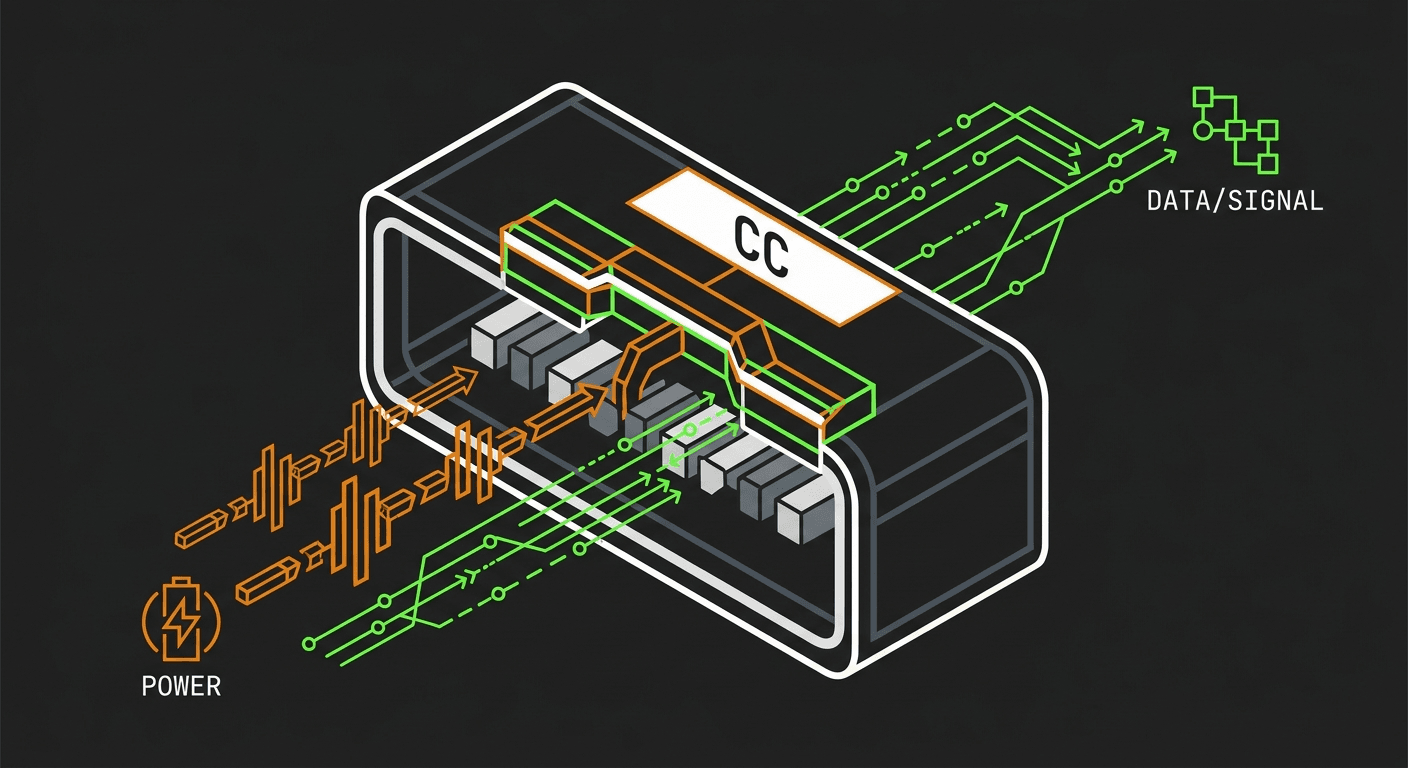
TL;DR: USB-C devices don't melt when connected to high-wattage chargers because of dynamic negotiation over a dedicated Configuration Channel (CC) pin. Using the USB Power Delivery (PD) protocol, the
TL;DR: Tired of AI agents writing sloppy, off-target code? The "To-Do" method restores fine-grained control inside your IDE. By dropping explicit inline comments (like // TODO: agent - refactor this)
In software engineering, optimizing for individual metrics at the expense of your team is a losing strategy. I believe that while "selfish" coding yields quick short-term wins, long-term career compou
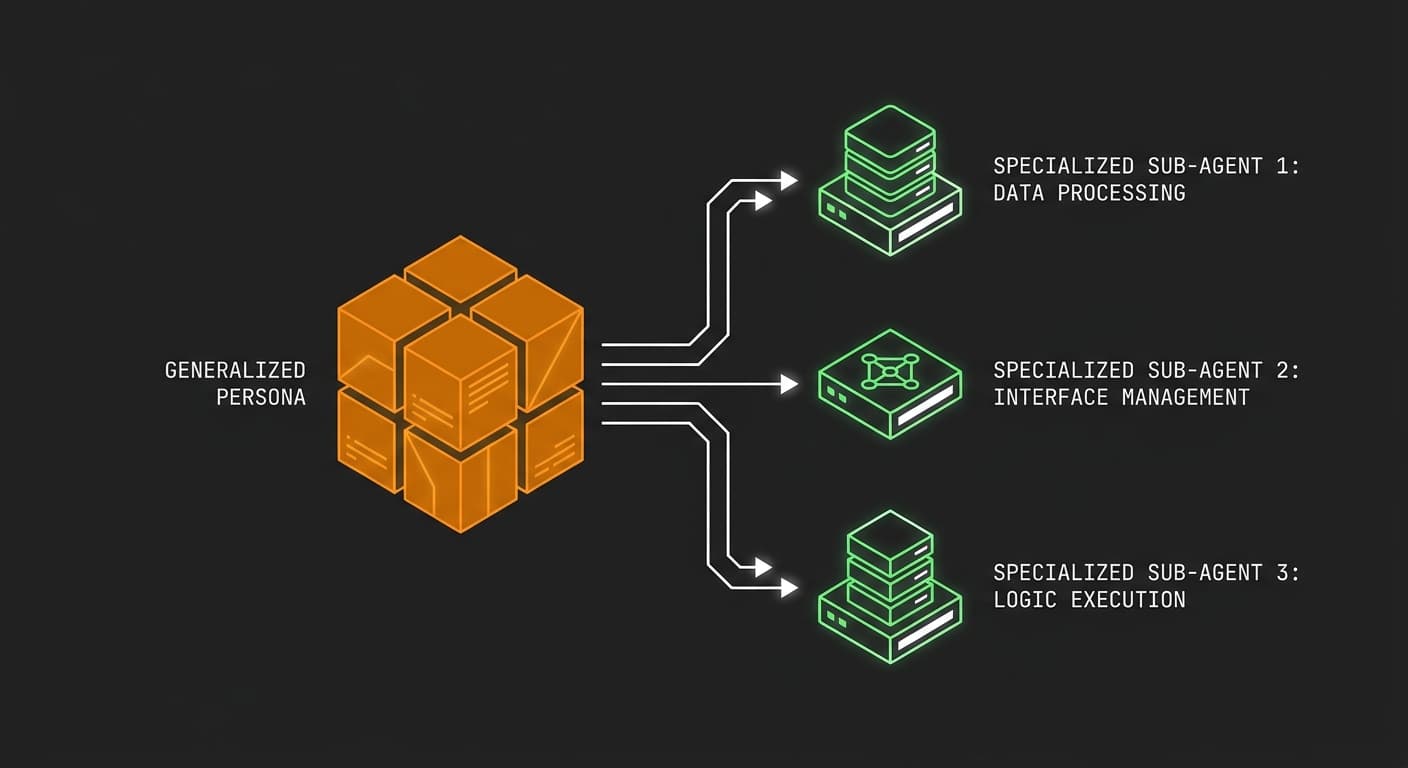
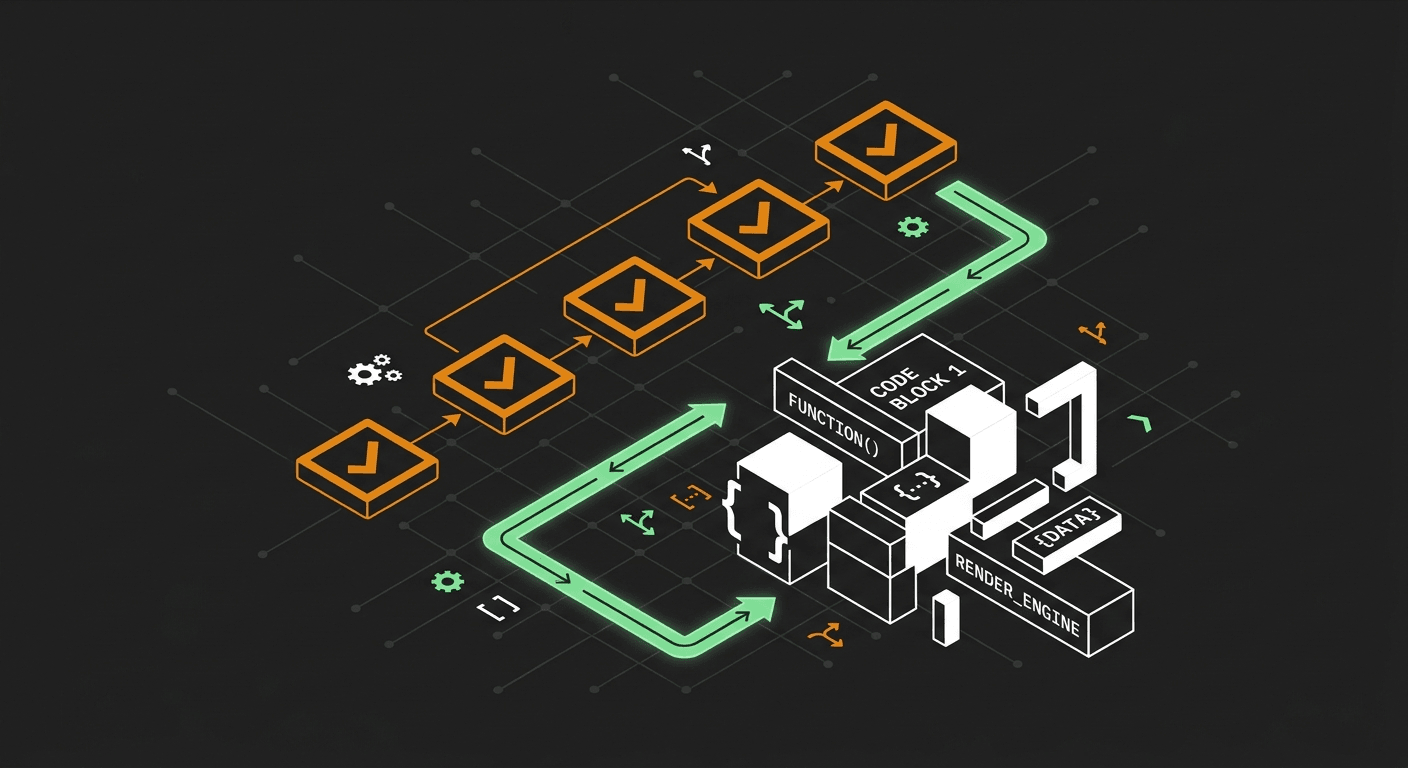
Quick Answer: When building multi-agent AI systems, assigning human personas with broad responsibilities is a trap. Instead, apply the single-responsibility principle. By breaking complex tasks down into highly focused sub-agents—like dedicated file searchers and isolated code writers—you reduce context exhaustion and make debugging significantly easier.
I've noticed a trap we fall into when designing AI sub-agents: we tend to imagine them as people. When I sit down to write my agent files, the natural inclination is to give them a job title. I might assign a persona like "expert full-stack developer" and expect that single entity to handle everything from searching the codebase to writing the final implementation. But I think that kind of thinking stilts us. Agents work best when they have a single responsibility, not a generalized human identity.
Multi-purpose agents fail because large language models struggle to maintain context and attention across overlapping responsibilities. When you force an agent to juggle multiple types of operations, it inevitably exhausts its context window, loses track of the initial instructions, and generates inaccurate outputs.
Let's say you are building a standard backend application. You wouldn't deploy a single monolithic function that directly handles database migrations, user authentication, and parsing external APIs all in the same process. It becomes a nightmare to scale and maintain. The same logic applies to AI. When I expect an agent to navigate a file system, understand the broader architectural context, and output the correct syntax changes simultaneously, I am forcing a monolith onto an LLM.
The technical bottleneck here is attention mechanism dilution. If a "coding agent" has system instructions detailing how to grep directories, how to analyze business logic, and how to format Python output, the prompt is overloaded. The LLM has to split its attention across deciding what action to take versus how to execute it well.
You apply the single responsibility principle by stripping away the human persona and focusing entirely on atomic functions. Instead of creating a general "coding agent," you design discrete sub-agents that handle searching, analyzing, and writing as completely isolated steps.
This closely mirrors the classic Unix philosophy: write tools that do one thing and do it well. Instead of giving one agent a massive toolset, I break the task down into distinct operations.
Here is how you can restructure a broad persona into highly effective, single-purpose sub-agents:
| Traditional Persona | Task-Based Sub-Agent | Core Responsibility |
|---|---|---|
| "Full-Stack Coder" | File Searcher | Rapidly scanning directories and retrieving only the file paths relevant to a specific query. |
| "Full-Stack Coder" | File Analyzer | Inspecting code logic to identify required changes, without permission to alter files. |
| "Full-Stack Coder" | File Writer | Taking the completed analysis and executing the exact syntax changes to generate a new file. |
By passing state between these focused agents, you keep the context window tight. If you are using a state graph pattern, the routing logic remains straightforward and modular:
def code_update_workflow(state):
# 1. Searcher strictly finds relevant file paths
paths = file_searcher_agent.invoke(state.query)
# 2. Analyzer strictly plans the logic changes
diff_plan = file_analyzer_agent.invoke(paths)
# 3. Writer strictly outputs the new file content
final_code = file_writer_agent.invoke(diff_plan)
return final_code
Laser-focused sub-agents provide highly reusable, modular building blocks that simplify debugging and prevent context exhaustion. Because their scope is restricted, they excel at their individual tasks and fail in predictable, traceable ways.
Debugging a generalized agent is notoriously difficult. If my "expert developer agent" writes a bad piece of code, I have to guess where the breakdown occurred. Did it search the wrong directory? Did it misunderstand the existing logic? Did it just mess up the syntax?
When I split these responsibilities into sub-agents, observability improves. I can look at the output of the file_searcher_agent and see exactly which files it retrieved. If the retrieved files are correct but the code is wrong, I know the file_analyzer_agent or file_writer_agent failed. I don't have to rewrite a massive, fragile system prompt; I just tweak the specific prompt for the isolated step. You end up with generically capable sub-agents that can be plugged into almost any workflow. It is an architectural shift I want to play around with more.
You orchestrate them using a main routing agent or a state graph framework. The orchestrator manages the workflow execution, ensuring the specific output of one sub-agent (like a list of file paths) becomes the direct input for the next, keeping their contexts completely isolated.
It can increase token usage because you are passing context back and forth between multiple API calls. However, I've found this cost is typically offset by the reduction in retries, error loops, and wasted tokens that happen when a monolithic agent loses focus.
The prompt should be specific enough that the agent only has one clear objective and output format. If you find yourself using conditionals like "if the file exists, analyze it, but if not, search again" in the system prompt, the task is likely too broad and should be split.