Why High Deployment Frequency Is The Secret To Software Stability
Deploying code more often sounds risky, but it is actually the safest way to ship. By breaking releases into tiny, frequent updates, you minimize the blast radius of bugs and make debugging trivial. High deployment frequency, a core DORA metric, transforms software delivery from a monthly crisis into a non-event.
When a team gets nervous about production bugs, they usually decide to 'slow down' to increase stability. They move from weekly deployments to monthly ones, thinking that more time for QA and more 'eyes on the code' will save them. It is a trap. When you hold onto enormous wads of software for a month, you are not making things more stable; you are just building a bigger bomb.
Stability is a byproduct of speed. If you want a more reliable system, you do not need more meetings—you need to ship smaller things, more often. If you are optimizing for deployment frequency, you are deploying lots of teeny tiny things all the time. These are easy to understand, easy to deploy, and easy to debug.
Why does deploying more often reduce software bugs?
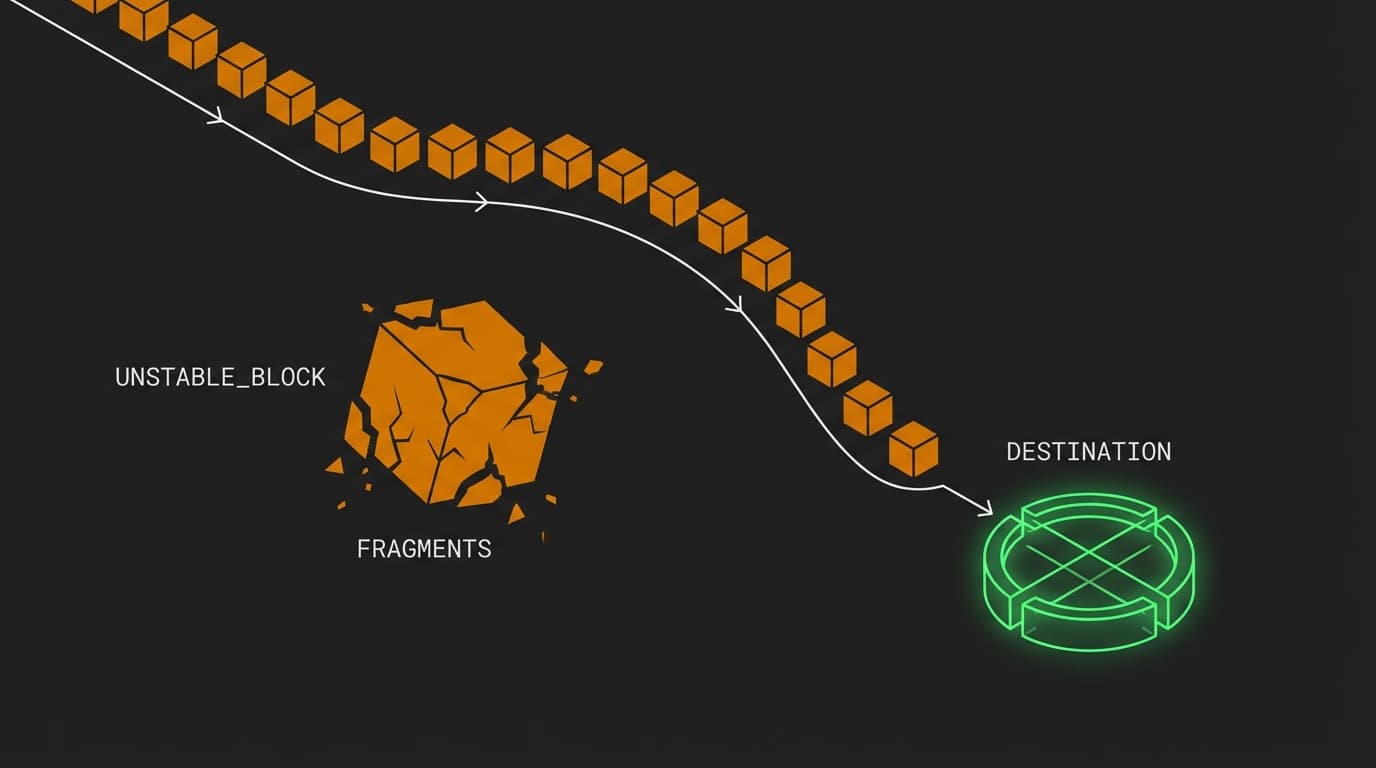
Small changes have a minimal blast radius. One commit equals one place to look when things break, making recovery a non-event.
Imagine building a complex Lego set. If you add one brick at a time and the structure starts to wobble, you know exactly which brick caused the issue. You pull it off and fix the placement. Now, imagine trying to glue five hundred bricks together in a dark room and only turning the lights on at the end of the month. If the structure is crooked, where do you even start?
That is what a monthly deployment feels like. You are pushing hundreds of commits into production at once. When the site goes down, you are not looking for a single bug; you are looking for an interaction between five different bugs hidden across twenty different files.
How does batching releases increase technical risk?
Hoarding code creates 'dependency hell' where multiple changes from different developers overlap in unpredictable ways. This complexity makes it impossible to isolate the root cause of a failure, leading to longer downtime.
| Deployment Strategy | Change Size | Debugging Effort | Mean Time to Recovery (MTTR) |
|---|---|---|---|
| Continuous Delivery | 1-2 Commits | Minutes (One file changed) | Low (Seconds) |
| Bi-Weekly Sprints | 50 Commits | Hours (Multiple dependencies) | Medium (Hours) |
| Monthly Release | 500+ Commits | Days (System-wide impact) | High (Days) |
How do I improve deployment frequency without breaking production?
Decouple deployment from release using feature flags. This allows you to push code to production constantly while keeping new logic hidden from users until it is fully verified.
Start with a simple toggle. You can ship the underlying logic for a new feature today, but keep it 'off'. This keeps your main branch fresh and prevents the dreaded 'merge day' where you spend six hours resolving conflicts because you have been sitting on a branch for three weeks.
// A simple feature gate
const isNewDiscountLogicEnabled = false;
function calculatePrice(cart) {
if (isNewDiscountLogicEnabled) {
return applyComplexNewDiscount(cart);
}
return applyLegacyDiscount(cart);
}
Tiny changes are easy to reason about. If the server's memory usage spikes right after you push this, even if the flag is off, you know the issue is likely in the initialization of that new module. You have one place to look.
Is high deployment frequency a metric for speed or quality?
Deployment frequency is a proxy for both because it measures the health of your entire CI/CD pipeline. High performers use frequency as a tool to force better automated testing and more modular architecture.
If you commit to deploying ten times a day, you cannot do it manually. You are forced to automate your testing. You are forced to improve your monitoring. You are forced to make your architecture more modular. These 'side effects' of chasing a high deployment frequency are exactly what create a stable, resilient system.
When we hoard code, we are essentially saying we do not trust our process. When we deploy every commit, we are proving that our process works. Cheers to shipping small and sleeping better.
FAQ
Does deployment frequency require 100% test coverage?
No, but it requires high-confidence coverage. You do not need every line tested, but you do need your critical paths, like login and checkout, to be protected by automated smoke tests that run on every push.
What is the biggest blocker to frequent deployments?
Usually, it is a manual approval process or a 'release train' culture. Breaking these bottlenecks requires shifting left on security and QA, allowing automated gates to replace manual sign-offs.
How does deployment frequency impact Mean Time to Recovery (MTTR)?
They are directly linked. Because frequent deployments involve smaller changes, identifying the 'bad' change is faster, which significantly lowers the time it takes to restore service when an outage occurs.




